Every now and then I bump into the Hackage Dependency Monitor and wish there was something similar for NuGet. Node.js also has something like this with David. As a maintainer of several packages, it would come in handy if something would tell me when a dependency gets outdated, instead of having to find out through a bug report or reading the new release announcement by coincidence.
Since NuGet exposes its repository through an OData feed, and .NET has some good facilities to query these, I thought it’d be fun to try to implement the core of a dependency monitor.
Exploration
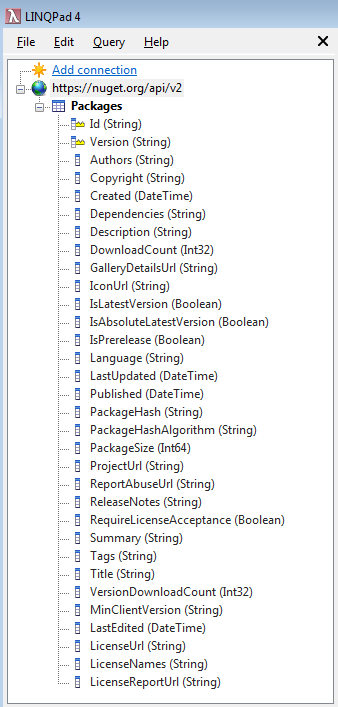
I started out with LINQPad, which makes exploration as easy as it gets. Click “add connection”, select the OData driver, and enter the feed URL https://nuget.org/api/v2 . That’s it. Open the connection and it shows the available tables (only "Packages" in this case) and their schema:
For example, we can find out how many projects are hosted on Github:
Packages .Where(x => x.IsLatestVersion && x.IsAbsoluteLatestVersion && x.ProjectUrl.Contains("github")) .Count()
Here are the figures for the most popular project hosting services (for the packages that have the ProjectUrl property defined):
Github: 5378
Codeplex: 2658
Google: 483
Bitbucket: 415
We can also see that dependencies are stored as a string… what does the content look like? Let’s find out:
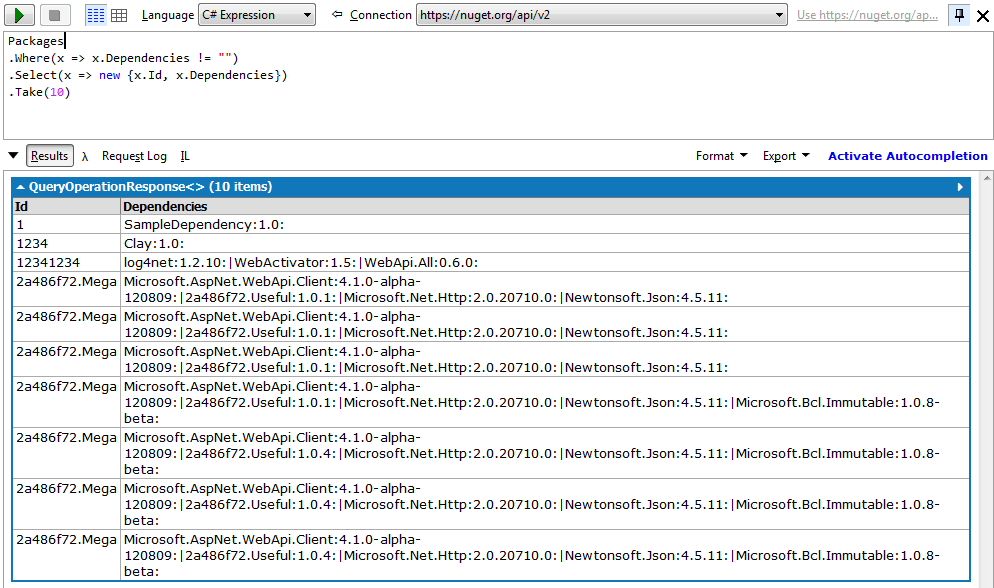
This means that we’ll have to parse this dependency string and run another query to fetch and analyze dependencies. So let’s switch to the F# REPL to write some code more comfortably.
Some helpers
NuGet has some functions that will come in handy to parse these dependency versions:
#r "System.Xml.Linq" #r @"g:\prg\SolrNet\lib\NuGet.exe" open NuGet let split (c: char) (x: string) = x.Split c let parseDependencies : string -> seq<string * IVersionSpec> = split '|' >> Seq.map (split ':' >> fun x -> x.[0], VersionUtility.ParseVersionSpec x.[1])
To query the NuGet feed we’ll use the OData type provider.
Unfortunately, WCF Data Services doesn’t support Contains(), which we need to get all the dependencies for a package in a single query. As an example, running this on LINQPad:
Packages.Where(x => new[] {"GDataDB", "FSharpx.Core"}.Contains(x.Id))
throws NotSupportedException: the method ‘Contains’ is not supported.
The type provider uses the same query translator underneath so it has the same limitation. OData v3 supports the Any() operator, but it seems that the NuGet feed is OData v2, so that doesn’t work either. Anyway, we can implement this with some quotation manipulation:
open Microsoft.FSharp.Quotations open Microsoft.FSharp.Quotations.Patterns let inList (memberr: Expr<'a -> 'b>) (values: 'b list) : Expr<'a -> bool> = match memberr with | Lambda (_, PropertyGet _) -> match values with | [] -> <@ fun _ -> true @> | _ -> values |> Seq.map (fun v -> <@ fun a -> (%memberr) a = v @>) |> Seq.reduce (fun a b -> <@ fun x -> (%a) x || (%b) x @>) | _ -> failwith "Expression has to be a member"
You can compare this with the equivalent C# code, it really shows how expression splicing makes the F# code much clearer.
Also, just for kicks, let’s run the query asynchronously. This doesn’t make much difference now as we’ll run this in the REPL, but it would be useful if this were to be used in a server.
#r "System.Data.Services.Client" #r "FSharp.Data.TypeProviders" open System.Linq open System.Data.Services.Client let execQueryAsync (q: _ DataServiceQuery) = Async.FromBeginEnd(q.BeginExecute, q.EndExecute)
Main code
Ok, enough with the helper functions. Here’s the main function:
type nuget = Microsoft.FSharp.Data.TypeProviders.ODataService<"https://nuget.org/api/v2"> type Package = nuget.ServiceTypes.V2FeedPackage let ctx = nuget.GetDataContext() let checkDependencies packageId = async { let packagesQuery = query { for p in ctx.Packages do where (p.Id = packageId && p.IsAbsoluteLatestVersion && p.IsLatestVersion) select p } :?> DataServiceQuery<Package> let! packages = execQueryAsync packagesQuery let package = Seq.exactlyOne packages let deps = parseDependencies package.Dependencies |> Seq.toList let depIds = List.map fst deps let depsQuery = query { for p in ctx.Packages do where (((%(inList <@ fun (x: Package) -> x.Id @> depIds)) p) && p.IsAbsoluteLatestVersion && p.IsLatestVersion) select p } :?> DataServiceQuery<Package> let! depPackages = execQueryAsync depsQuery let depPackagesList = Seq.toList depPackages let satisfies = deps |> List.map (fun (depId, version) -> let depPackage = depPackagesList |> Seq.find (fun p -> p.Id = depId) let semVersion = SemanticVersion.Parse depPackage.Version depId, version, version.Satisfies semVersion) return satisfies }
This returns a list of tuples where the first element is the package ID of the dependency, the required version for that dependency, and a boolean saying if the dependency is outdated (false) or not (true).
Let’s try an example:
checkDependencies "GDataDB" |> Async.RunSynchronously
Gives:
[("Google.GData.Client", [2.1.0.0] {IsMaxInclusive = true;
IsMinInclusive = true;
MaxVersion = 2.1.0.0;
MinVersion = 2.1.0.0;}, false);
("Google.GData.Extensions", [2.1.0.0] {IsMaxInclusive = true;
IsMinInclusive = true;
MaxVersion = 2.1.0.0;
MinVersion = 2.1.0.0;}, false);
("Google.GData.Documents", [2.1.0.0] {IsMaxInclusive = true;
IsMinInclusive = true;
MaxVersion = 2.1.0.0;
MinVersion = 2.1.0.0;}, false);
("Google.GData.Spreadsheets", [2.1.0.0] {IsMaxInclusive = true;
IsMinInclusive = true;
MaxVersion = 2.1.0.0;
MinVersion = 2.1.0.0;}, false)]
Uh-oh, I better update those dependencies!
Conclusion
So this looks simple enough, right? However, I consider this just a spike, it’s not really robust. What happens if the package doesn’t exist? Exception. Ill-defined dependencies? Exception.
Still, it shouldn’t be too hard to make this more robust, then put it in a web server and done! Easier said than done ;-)
Also, it seems that the NuGet v3 API won't be based on OData so this whole experiment might need to be rewritten soon.
Anyway, here's the entire code for this post.
Appendix: WCF Data Services criticism
I generally dislike expression-based translators (i.e. IQueryable) because they’re usually eminently partial, i.e. you have to guess what’s supported, read the docs very carefully, or run your code in a test and see what happens. Otherwise you get exceptions everywhere. The compiler can’t do much and it’s never quite clear what will execute on the client and what will be translated and executed on the server. This hurts your ability to reason about the code, which in turn means more programming by coincidence.
WCF Data Services takes this to pathological levels. While exploring the NuGet feed in LINQPad I found many simple expressions that should have worked but didn’t. A few examples:
Packages.Where(x => new[] {"GDataDB", "FSharpx.Core"}.Contains(x.Id))
This is the one I mentioned earlier. I don’t see why the expression translator couldn’t do what I did and compile this to a chain of OR’ed expressions.
Even the simplest projection fails:
Packages.Select(x => x.Id)
Throwing NotSupportedException: Individual properties can only be selected from a single resource or as part of a type. Specify a key predicate to restrict the entity set to a single instance or project the property into a named or anonymous type.
I have no idea what the first part of that error means, but projecting to an anonymous type works:
Packages.Select(x => new {x.Id})
The official explanation for this is that the OData protocol doesn’t support it, but again, it would seem that this is the job of the expression translator and the protocol or server side of things has little to do with it.
By the way, if you happen to add a Take() operator you get a totally different exception:
Packages.Select(x => x.Id).Take(20)
Throws an InvalidCastException: Unable to cast object of type 'System.Data.Services.Client.NavigationPropertySingletonExpression' to type 'System.Data.Services.Client.ResourceSetExpression'.
Or add a condition and you get yet another different error:
Packages .Where(x => x.IsLatestVersion && x.IsAbsoluteLatestVersion) .Select(x => x.Id) .Take(10)
NotSupportedException: Can only specify query options (orderby, where, take, skip) after last navigation.
Which is incorrect, since replacing the projection in the above expression with an anonymous type works fine.
In this other example, the library doesn’t process negated conditions correctly, which causes a cryptic server-side exception:
Packages .Where(x => !x.ProjectUrl.Contains("google")) .Select(x => new {x.Id})
“An error occurred while processing this request. InnerException: Rewriting child expression from type 'System.Nullable`1[System.Boolean]' to type 'System.Boolean' is not allowed, because it would change the meaning of the operation. If this is intentional, override 'VisitUnary' and change it to allow this rewrite.”
The generated URL from this expression is: https://nuget.org/api/v2/Packages()?$filter=not substringof('google',ProjectUrl)&$select=Id which apparently isn’t supported server-side.
But change the condition from using the “not” operator to “== false” and everything is magically fixed:
Packages .Where(x => x.ProjectUrl.Contains("google") == false) .Select(x => new {x.Id})
Generated URL: https://nuget.org/api/v2/Packages()?$filter=substringof('google',ProjectUrl) eq false&$top=10&$select=Id
These two expressions are logically equivalent, but one works and the other one fails:
Packages .Where(x => x.IsLatestVersion) .Select(x => new {x.IsLatestVersion})
Packages .Select(x => new {x.IsLatestVersion}) .Where(x => x.IsLatestVersion)
The second one fails with: “NotSupportedException: The filter query option cannot be specified after the select query option.”.
These are all very simple expressions and I found all of these issues in about one hour of experimentation in LINQPad (for reference, LINQPad v4.47.02 using WCF Data Services 5.5), so be very careful and test every single call if you have to use WCF Data Services. And keep in mind that if you use the OData F# type provider, you’re also using WCF Data Services, so the same warning applies.

